Concepts#
Semaphore manages your build, test, and deployment workflows with pipelines, blocks, and promotions:
- Workflows may contain multiple pipelines, e.g. one to run tests and another for deployment.
- Blocks define what to do at each step in the pipeline.
- Blocks run in agents that define the hardware and software environment.
- Promotions connect different pipelines.
All configuration is specified in YAML files. The initial pipeline is always
sourced from .semaphore/semaphore.yml. Additional pipelines triggered via
promotions are defined in separate files.
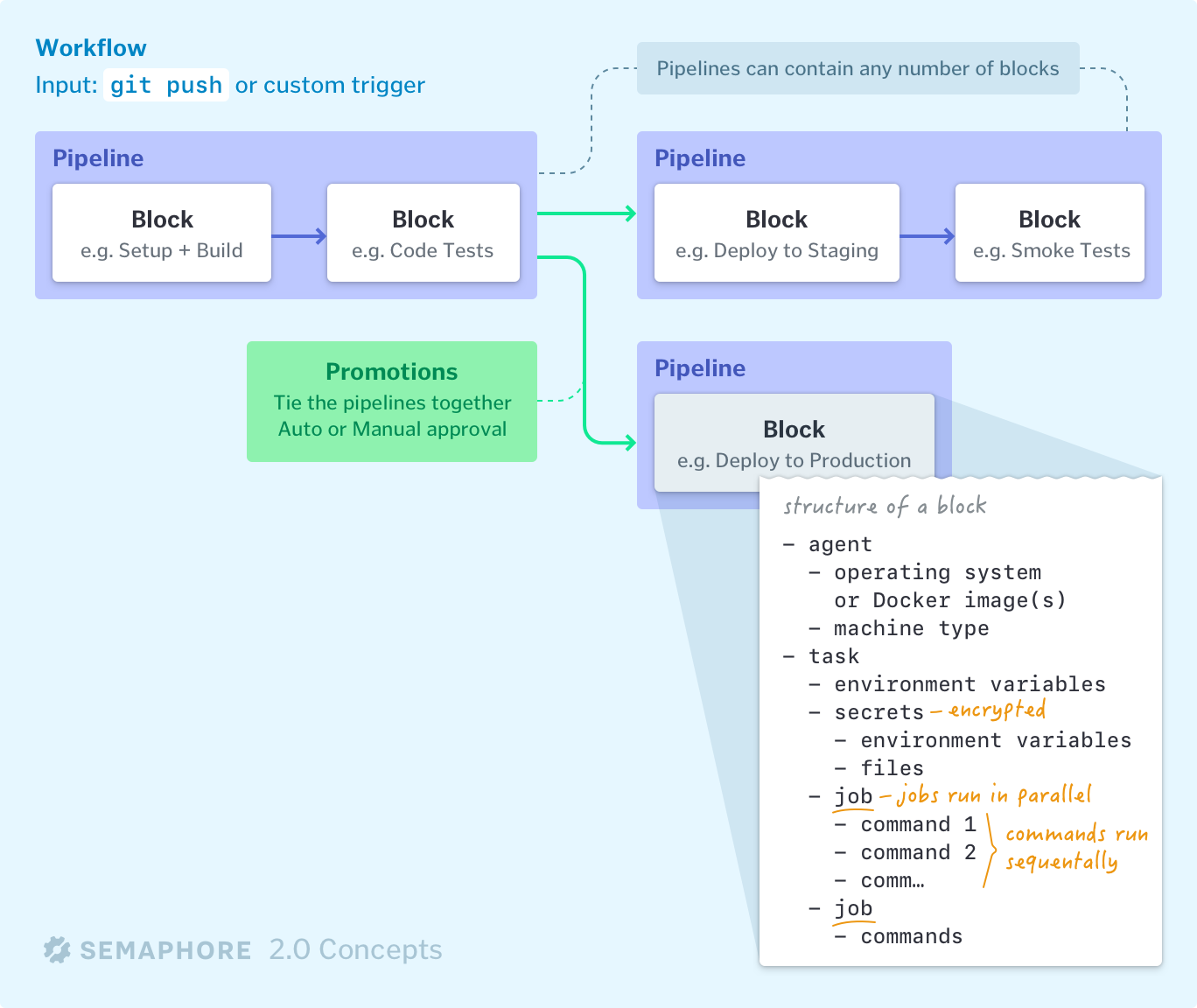
Blocks & Tasks#
Blocks are the building blocks of a pipeline. Each block has a task defined by one or more jobs. Jobs specify the commands to execute.
If your task contains multiple jobs, Semaphore will execute them in parallel.
Each job runs in a separate, isolated machine that boots a clean environment.
For example, a Tests task may define jobs for running unit and integration
tests in parallel, making the task finish faster.
By default, blocks run sequentially, waiting for all tasks in the previous block to complete before continuing. However, you can also define your pipeline as a dependency graph or run blocks in parallel by defining block dependencies.
Each task can configure its own environment (including machine type), set its own environment variables, and use any predefined secrets.
For an introduction to creating blocks, tasks and jobs, refer to the getting started guide. You can also refer to the pipeline reference documentation.
Promotions#
Promotions are junction blocks in your workflow. Promotions are commonly used for deployment and promoting builds to different environments. A pipeline can have multiple promotions. Promoting loads an entirely new pipeline, so you can build complex pipelines using only configuration files.
To see how to manage deployments using promotions, refer to the promotions reference documentation.
Secrets#
Secrets are used to store and retrieve sensitive data, such as API keys,
which should never be committed to source control. Semaphore securely manages
sensitive data for use in blocks and tasks via encrypted environment variables
or files. You can create a secret using the sem CLI and reference it in
the pipeline YML definition.
To see how to define and use secrets, refer to the secrets documentation.
Agents, Machines, and Containers#
Semaphore makes sure that there are always agents ready to run all your jobs. When configuring an agent, you can select from a number of memory/CPU combinations and virtual machine (VM) operating system environments.
The Ubuntu Linux and MacOS VM environments have
common build tools and programming languages pre-installed, so you can
run your code without the overhead of installing numerous dependencies in
every workflow. Agents provide you with full sudo access, so you can install
additional software when needed.
Agents can also use custom Docker containers to run your jobs. This is an alternative to using Semaphore VMs, which gives you complete control over your CI/CD environment.
More reading: