FAQ
This page contains Frequently Asked Questions.
Architecture
Is there a list of the platform IPs used by Semaphore?
Yes. The list of the platform IPs used by Semaphore is publicly available. You may whitelist these IPs in your firewall to allow access to all Semaphore services.
Can I use my own machines to run workflows?
Yes. With the Semaphore Hybrid Plan you can add your own machines as self-hosted agents. You can use a mix of Semaphore Cloud and your own machines for your workflows.
Can I run Semaphore On-Premise?
Yes. The Semaphore On-Premise Plan allows you to host a separate installation of Semaphore behind your firewall, allowing you to run CI/CD completely on your own infrastructure.
Can I use self-signed certificates with private Docker registries?
Yes. To use a private Docker registry with a self-signed SSL certificate you must:
-
Import the self-signed certificate files as a secret with the filename
domain.crt -
Use the following command to your pipeline:
sudo mv $SEMAPHORE_GIT_DIR/domain.crt /etc/docker/certs.d/myregistrydomain.com:5000/ca.crt
This will allow a connection to a private remote registry using the provided certificate.
Billing
How do I track spending?
You can get insights about your spending, and past invoices, and update your plan on the Plans & Billing page.
To access this page:
- Open your organization menu
- Select Plans & Billing
Can I set budget alerts?
Yes. Organizations Owners and Admins can set up budget alerts.
To set up a budget alert:
-
Open your organization menu
-
Select Plans & Billing
-
Click on Update next to Spending budget limits
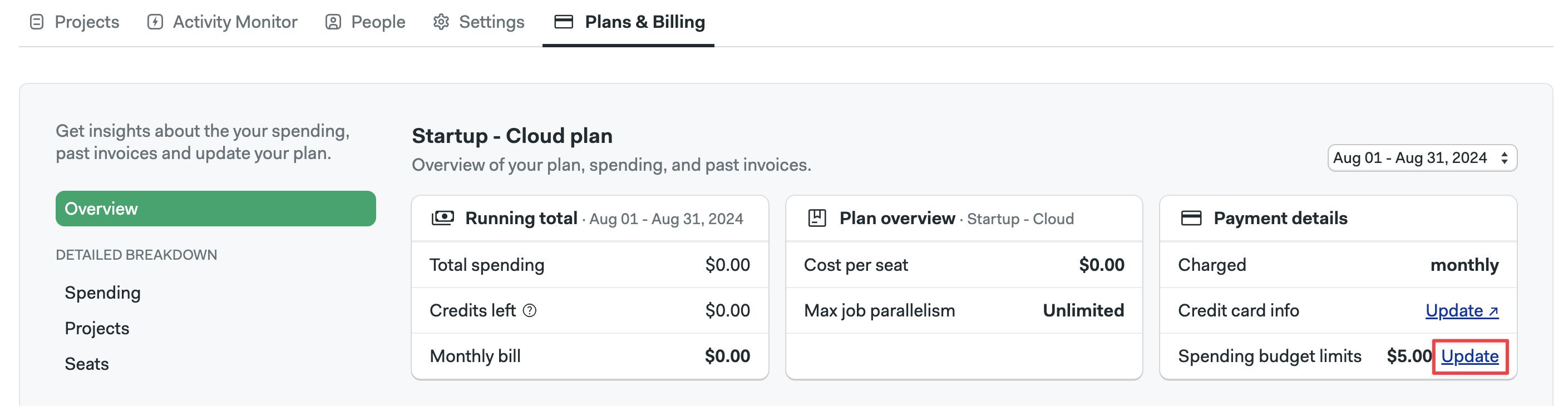
-
Set the alert value and the email address
Semaphore will send alerts when your organization has spent 50%, 90%, and 100% of the budget.
Pipelines are not be disabled if you go over budget.
How do I change my payment method?
In order to change your credit card or PayPal information, follow these steps:
-
Open the organization menu
-
Select Plans & Billing
-
Under Payment details click on Update
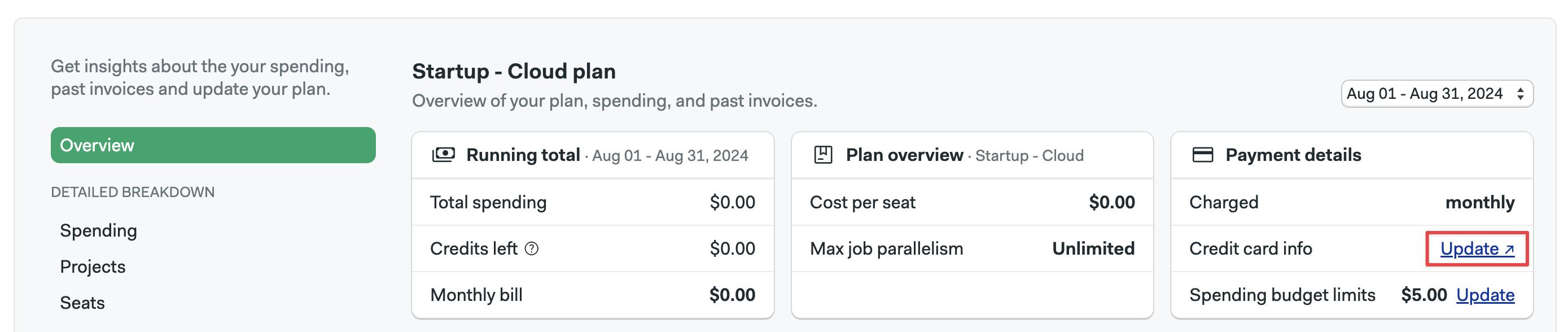
-
Go to the Subscriptions tag
-
Press Manage and then Update payment method
-
Type the new information
Can I change my billing information?
Yes. If you want to change the recipient name, company name, address, phone number, billing email, VAT ID, or country on the invoice, please get in touch with us at: support@semaphoreci.com
Billing change requests must originate from a user with Admin or Owner permissions on the organization, or from the current Billing contact associated with the organization’s FastSpring subscription. This is for security reasons, ensuring that only authorized individuals can change the billing information.
Can I change my VAT number?
Not directly from the Semaphore website. After a subscription has been purchased, users can't add or change a VAT number (VAT ID) from the UI.
If you wish to change the VAT number associated with your subscription, please get in touch with support@semaphoreci.com with the VAT number you want to add and we will gladly make it happen.
For security reasons, these requests must originate from an email linked to a user with the Owner role, or from the current Billing contact associated with the organization’s FastSpring subscription. This ensuress that only authorized individuals can make changes to the billing information.
Will I get an invoice?
Yes. You will receive an invoice for your organization at the end of each billing period. This invoice will be sent to the email address that was entered when payment info was added.
You can also find your invoices at the bottom of the Plans & Billing in your organization menu.
What is your refund policy?
Apart from cases of extended downtime (multiple hours in a day, or multiple days in a month), we do not offer refunds.
We will, however, consider requests for refunds in extenuating circumstances. If you would like to request a refund, please email us at billing@semaphoreci.com and our team will do what we can to work out a solution.
Please include the affected Workflow ID when contacting our Billing team regarding refunds.
Why are you still charging my old credit card?
If you’ve added a new credit card to the subscription, but the old one is still being charged, it means that the new credit card wasn't properly marked for usage.
Here’s how to do that:
-
Open the organization menu
-
Select Plans & Billing
-
Under Payment details click on Update
-
Go to the Subscriptions tab
-
Press Manage and then Update payment method
-
Press Use this next to the credit card you'd like to use
After that, you can also remove the old credit card if you don't need it anymore.
Why can't I remove my old credit card?
If you run into this situation, it means that the old credit card is still in use. In order to mark the new credit card for usage, you can:
-
Open the organization menu
-
Select Plans & Billing
-
Under Payment details click on Update
-
Go to the Subscriptions tag
-
Press Manage and then Update payment method
-
Press Use this next to the credit card you'd like to use
After that, you’ll be able to remove the old credit card.
Git, GitHub and BitBucket
Can I build a project with git submodules?
Yes. To do that, follow these steps:
Make sure that Semaphore has permissions to clone your submodules repository.
Can I redeliver webhooks from Github to Semaphore?
Yes. Rarely Semaphore does not receive a webhook from GitHub. This results in a workflow not being triggered. When this happens, you can redeliver the webhook to trigger the workflow.
These are the steps to redeliver webhooks from Github:
- Go to your repository on GitHub
- Click Settings
- Click Webhooks
- Click Edit for the webhook you want to redeliver
- Scroll down to Recent Deliveries and search for the one that failed
- Press the ... symbol, then Press Redeliver
Can I send a comment on a pull request on GitHub from a workflow?
Yes. You can use the GitHub API to comment on pull requests.
For example:
curl -X POST -H "Authorization: token <OAUTH_TOKEN>" \
https://api.github.com/repos/<owner>/<repo-name>/issues/<number>/comments \
-d '{"body":"body"}'
Pipelines
Can I insert multiline commands?
Yes. You can only add multiline commands by editing the pipeline YAML file directly.
To create a multiline command begin the command with >-. For example:
commands:
- >-
if [ "foo" = "foo" ];
then commands...;
else commands...;
fi;
There are two other indicators you can use:
-
Block Style Indicator: The block style indicates how new lines inside the block should behave. If you want to keep each line as a new line, use the literal style, indicated by a pipe
|. If you want them to be replaced by spaces instead, use the folded style, indicated by a right angle bracket>. -
Block Chomping Indicator: The chomping indicator controls what should happen with new lines at the end of the string. The default, clip, puts a single newline at the end of the string. To remove all new lines, strip them by putting a minus sign
-after the style indicator. Both clip and strip ignore how many new lines are actually at the end of the block; to keep them all put a plus sign+after the style indicator.
Can I use different agents in the same pipeline?
Yes. Use the agent override in a block to use a different agent.
Can I use YAML anchors in Semaphore?
Yes. Semaphore uses YAML version 1.2 and it accepts all official YAML features.
The following example of uses anchors and aliases:
version: v1.0
name: Aliases test
agent:
machine:
type: e1-standard-2
os_image: ubuntu2004
blocks:
- name: Block 1
task:
prologue: &common_prologue
commands:
- echo hello
jobs:
- name: Job 1
commands:
- echo hello1
- name: Block 2
task:
prologue: *common_prologue
jobs:
- name: Job 2
commands:
- echo hello2
- name: Block 3
task:
jobs:
- name: Job 3
commands:
- echo hello3
Can I dynamically define or create pipelines?
Yes. Semaphore provides template support on parameterized promotions.
Can I change the timezone?
The default timezone is UTC. The timezone can be changed in 2 ways in Linux agents:
- Assign a different value to the TZ environment variable:
export TZ=Europe/Belgrade
- Create a symlink in
/etc/localtimeto one of the available timezones:
sudo ln -sf /usr/share/zoneinfo/Europe/Belgrade /etc/localtime
Can I change the PostgreSQL locale?
Yes. Semaphore uses sem-service to provide different versions of databases. This tool uses Docker containers instead of traditional Linux services. So, the traditional way of changing locales no longer works, as it does not affect containers.
The following recipe provides an altered version of the container to sem-service. The database should be available as before, without modifying your application in any way:
-
Create a Dockerfile with the following content:
FROM postgres:9.6
RUN localedef -i pt_BR -c -f UTF-8 -A /usr/share/locale/locale.alias pt_BR.UTF-8
ENV LANG pt_BR.UTF-8 -
Rebuild the Postgres image using the locale:
docker build - -t postgres:<locale-tag> < Dockerfile -
Start the newly-created image:
docker run --rm --net host -d -e POSTGRES_PASSWORD=semaphore --name postgres -v /var/run/postgresql:/var/run/postgresql postgres:<locale-tag>
What tools can I use to split a test suite for parallel jobs?
We recommend using semaphore_test_boosters gem. This gem spreads tests across parallel jobs based on a configuration file or uniform file distribution.
Other options are also supported, e.g. Knapsack (both free and pro versions).
The following example splits the tests with Knapsack when job parallelism is enabled:
CI_NODE_TOTAL=$SEMAPHORE_JOB_COUNT CI_NODE_INDEX=$((SEMAPHORE_JOB_INDEX-1)) bundle exec rake 'knapsack:rspec'
Help! My job is stuck or stalled and won't end
The most common reason for stalled builds is a process that refuses to shut down properly. This is most likely a debug statement or a cleanup procedure in the catch procedure.
To debug the problem, first, attach a terminal to the stalled job with sem attach
Check the following possible causes:
- List the running processes with
ps auxortop. Are there any suspicious processes running? - Run a strace on the running process:
sudo strace -pto see the last kernel instruction that it is waiting for. For example,select(1, ...can mean that the process is waiting for user input. - Check the system metrics at
/tmp/system-metrics. This tracks memory and disk usage. Lack of disk space or free memory can result in stalling. - Check the Agent logs at
/tmp/agent_logs. The logs could indicate that an agent is waiting for certain conditions. - Check the Job logs at
/tmp/job_logs.json. The logs could indicate that a job is waiting for certain conditions. - Check the syslog as it can be also a valuable source of information: tail
/var/log/syslog. It can indicate 'Out of memory' conditions.
While an issue is ongoing, you might consider using a shorter execution_time_limit in your pipelines. This will prevent stale builds from running for a full hour.
Why is my job failing if all commands have passed?
This can happen because of code coverage tools, e.g. simplecov, which can be set to fail the test suite if a minimum coverage level is not achieved.
Why are tests passing locally but not on Semaphore?
The main reason for this behavior is differences in the stacks. As a first step, ensure that the same versions of languages, services, tools, and frameworks such as Selenium, browser drivers, Capybara, Cypress are used both locally and in the CI environment.
To achieve this, use sem-service, sem-version, and the OS package manager. Environment variables can also lead to unexpected behaviors, for instance, Semaphore will set CI=true by default.
If you are using Docker containers when performing tests, it's possible that, while the command itself runs instantly, the process will not be completely started, leading to certain endpoints not being available. Using a minimum sleep 10 can help in this scenario. Cypress has a wait-on module that provides similar functionality.
If the test passes and fails randomly with the same commit SHA, then you might be facing a flaky test.
Why my job is not starting?
You might be hitting the quota limitation. To see your activity across the organization
- Open the organization menu
- Select Activity Monitor
- Check your agent usage, jobs won't start until a suitable agent is free
You can also run sem get jobs to display all running jobs to confirm how much of the quota is being used.
Why does my job fail when I specify "exit 0" in commands?
Using the exit command closes the PTY and causes the job to fail. If this isn't the desired behavior, you can use the return 130 command and manually set SEMAPHORE_JOB_RESULT environmental variable.
To set the job as:
- Stopped: execute
return 130 - Stopped and successful:
export SEMAPHORE_JOB_RESULT=passed; return 130 - Stopped and failed:
export SEMAPHORE_JOB_RESULT=failed; return 130
Some commands like bash -e or set -x otrace may override this behavior and make it not function correctly.
Help! Docker fails with "toomanyrequests"
This is commonly due to a rate-limit of third-party providers such as Docker Hub. These services limit how many unauthenticated pulls you can do in an hour, often based on IP. The machine you are running your jobs on may have been provisioned for another user, resulting in that particular IP being rate-limited.
You can bypass this issue by creating a free account on Docker Hub, and then authenticating with Docker within the job. This way, the pulls are limited by your account (100 per hour), and not by the IP of the machine.
If you cannot authenticate, you can use other third-party Docker registries such as the ECR Public Gallery.
Pull request on GitHub is stuck
If you have a pull request stuck when using GitHub, check if you have renamed the pipeline recently. If you did, see how to fix stuck PRs on GitHub
Project
Can I transfer ownership of a project?
Yes. The following conditions need to be met:
- The new project owner needs to have Admin role for the repository
- The new owner needs to ensure that the GitHub connection or BitBucket connection is working
To change the project ownership:
- Open to the project
- Go to Settings
- In the General section, under Project Owner type the name of the new owner
- Press Change
After project ownership has been transferred, you need to push a new commit. Old workflows cannot be re-run after transferring ownership.
If you come across any issues, please reach out to support@semaphoreci.com and include the name of the project and the GitHub/Bitbucket username of the new owner in your message.
Can I rename a project?
Yes. To do that, follow these steps:
- Open the project you want to rename
- Go to Settings
- Type the new name for the project
- Press Save Changes
This can also be performed from the CLI by using the sem edit command.
Can I delete a project?
Yes. To delete a project:
- Open the project you want to rename
- Go to Settings
- At the bottom of the page, click on the link in the Delete Project section.
- Fill in the delete reason details
- Enter the project name for final confirmation.
- Press the Delete project button.
If you prefer using CLI, you can delete a project by using the sem delete command.
Deleting a project cannot be reversed.
Can I change the visibility of a project?
Yes. To make the project visible or private follow these steps:
- Open the project you want to rename
- Go to Settings
- Click the link next to Public or Private to toggle the visibility
- Press Save Changes
Why can't I make my project private?
This might be a limitation related to the plan your organization is using. Open-source and free plans cannot create private projects.
Workflows
How do I fix the error "Machine type and OS image for initialization job not available"
This can happen in self-hosted versions of Semaphore. The problem is that the agent that runs the initialization job is not defined or is defined but doesn't exist. To solve the error:
- Open your Organizations Settings menu
- Select Initialization job
- Select a valid agent types
- Press Save
Can I approve blocked workflow triggers?
If you are using a filter for contributors, you can still review and approve blocked pull requests by commenting with a /sem-approve message. Anyone who can run a forked pull request can also approve one.
Approving forked pull requests is limited to new comments only and is not possible for comment edits. Due to security concerns, /sem-approve will work only once. Subsequent pushes to the forked pull request must be approved again.
How do I fix the error "Revision: COMMIT_SHA not found. Exiting"
This happens when the repository receives pushed while Semaphore is still processing the incoming webhook. For example, when someone modifies or removes with a git rebase or git commit --amend command followed by a git push --force shortly after.
You can prevent this error by enabling the auto-cancel option in the pipeline.
Why are my workflows not running in parallel?
Git pushes to the same branch are queued by default. Pushes to different branches do run in parallel. You can use named queues in your pipelines to better control how workflows are parallelized or activate auto-cancel to stop running pipelines when new pushes arrive to the queue.
Why did my workflow stop without explanation?
The auto-cancel can stop running workflows when new pushes arrive. Check if this feature is enabled and what strategy are you using to ensure important workflows are not canceled.
Why aren't workflows triggering on pull requests?
Check that pull request triggers are enabled for the project. If they are, check if the pull request can be merged. Since Semaphore uses the merge commit to run the workflows, merge conflicts can prevent workflows from starting.
Why does my code contain tags that have already been deleted?
This may be due to using checkout --use-cache. When used in this fashion, code is cached and might contain stale tags.
You can solve the issue by not using the cache, i.e. using checkout without arguments, or by deducing the value of SEMAPHORE_GIT_CACHE_AGE. For example:
# set cache age to 12 hours
export SEMAPHORE_GIT_CACHE_AGE=43200
Why does my SSH debug job fail to start?
There are several possible error messages that appear when trying to initiate an SSH session. For example:
sem debug job 46490d81-2d0b-42ee-a2b0-371880dd5d9c
* Creating debug session for job '46490d81-2d0b-42ee-a2b0-371880dd5d9c'
* Setting duration to 60 minutes
error: http status 401 with message "Unauthorized" received from upstream
Or:
sem debug job 46490d81-2d0b-42ee-a2b0-371880dd5d9c
* Creating debug session for job '46490d81-2d0b-42ee-a2b0-371880dd5d9c'
* Setting duration to 60 minutes
error: http status 404 with message "{"code":5, "message":"Job 46490d81-2d0b-42ee-a2b0-371880dd5d9c not found", "details":[]}" received from upstream
The are several causes for these messages:
- You might have a typo in the job id
- You may need to connect the
semtool to your organization - You may need to use
sem contextto switch to the organization containing the project you want to debug
The message indicates that the SSH session cannot be initiated for the provided job id.
Why does autocomplete does not work in my SSH session?
Enabling the set -e option in the Bash shell causes autocomplete to fail and end the debugging session. Check that you are not using this option in any of your scripts and try again.
Why are my secrets empty?
We have discontinued exposing secret content via the CLI, API, and web interface to ensure enhanced security measures. Retrieval of secret values is now exclusively available through the job mechanism.