Jenkins
Overview
The main difference between Jenkins and Semaphore is that Semaphore is a managed service while Jenkins is purely self-hosted.
In Jenkins you are in charge of configuring everything, installing plugins for all the functionality you need, managing the agents to run the workflows, creating the connections to the Git providers, managing the Jenkins instance, and the list goes on.
Semaphore is always ready to use, once you create an account and connect your Git provider you're ready to go. There is nothing to manage and you get first-class support.
Jenkins vs Semaphore
This section describes how to implement common Jenkins functionalities in Semaphore.
Checkout
Checkout clones the repository in the CI system. This is usually near the beginning of every job and workflow.
- Jenkins
- Semaphore
In Jenkins, we use the Git plugin to connect and retrieve the repository history. You need to add authentication credentials on the Jenkins instance and use them in the stage.
stage('Checkout repository') {
steps {
git branch: 'main',
credentialsId: '<my-repo-auth>',
url: 'git@github.com:<owner>/<project-name>.git'
sh "cat README.md"
}
}
When we create a project in Semaphore, the Git repository is automatically linked to the project. To clone the repository we only need to execute checkout near the beginning of the job.
checkout
# now the code is the current working directory
cat README.md
Artifacts
Artifacts are used to store deliverables and persist files between runs.
- Jenkins
- Semaphore
In Jenkins we use archiveArtifacts to store files:
stage('Build') {
steps {
// Your build steps here
// ...
archiveArtifacts artifacts: 'build/output/**/*.jar', fingerprint: true
}
}
And copyArtifacts to retrieve them:
stage('Deploy') {
steps {
copyArtifacts(projectName: 'MyProject', filter: '**/*.jar', target: 'deploy-directory')
}
}
Semaphore provides an integrated artifact store that can be accessed with the artifact tool inside any job.
To store a file we use:
artifact push workflow build
We can restore the folder with:
artifact pull workflow build
Caching
The cache speeds up workflows by keeping a copy of dependencies in storage.
- Jenkins
- Semaphore
In Jenkins, we need to install the jobcacher plugin to enable the cache. Then, we a cache stage to the workflow before building the project.
stage('Cache Dependencies') {
steps {
cache(maxCacheSize: 250, caches: [
[$class: 'ArbitraryFileCache',
includes: ['**/node_modules/**'],
excludes: [],
path: 'node_modules',
fingerprintingStrategy: [$class: 'DefaultFingerprintStrategy']]
]) {
// Your build steps go here
sh 'npm install'
}
}
}
Semaphore provides an integrated cache that can be accessed with the cache cache tool.
checkout
cache restore
npm install
cache store
Language versions
We often need to activate specific language or tool versions to ensure consistent builds.
- Jenkins
- Semaphore
Jenkins doesn't have a native way to activate languages. That means you have to install a plugin or run the language installation commands manually in a stage.
stage('Setup Go') {
steps {
sh '''
source ~/.gvm/scripts/gvm
gvm install go1.21.0 # or whatever version you need
gvm use go1.21.0
go version
'''
}
}
stage('Build') {
steps {
sh 'go build'
}
}
Semaphore provides the sem-version tool to install and activate languages and tools.
sem-version go 1.21
checkout
go version
go build
Databases and services
Testing sometimes requires disposable databases and services in the CI environment.
- Jenkins
- Semaphore
Jenkins has plugins for various databases and services. It also supports running services with Docker, which is often the easiest way to run disposable instances.
stages {
stage('Start Database') {
steps {
sh 'docker run --name test-postgres -e POSTGRES_PASSWORD=mysecretpassword -d postgres'
// Wait for database to be ready
sh 'sleep 10'
}
}
stage('Run Tests') {
steps {
sh 'npm test'
}
}
stage('Cleanup') {
steps {
sh 'docker stop test-postgres'
sh 'docker rm test-postgres'
}
}
}
Semaphore provides the sem-service tool which uses Docker containers to automatically start and manage popular databases and other services.
There is no need to clean-up or stop the service once used as the job environment is scrapped once the commands are done.
sem-service start postgres
checkout
npm test
Secrets
Secrets inject sensitive data and credentials into the workflow securely.
- Jenkins
- Semaphore
In Jenkins, we create the credentials at the instance level and then initialize variables using the credentials id.
environment {
AWS_ACCESS_KEY_ID = credentials('jenkins-aws-secret-key-id')
AWS_SECRET_ACCESS_KEY = credentials('jenkins-aws-secret-access-key')
}
// later in stages ...
stage('AWS S3 Access') {
steps {
sh 'aws s3 ls'
}
}
In Semaphore, we create the secret at the organization or project level and activate it on a block.
The secret contents are automatically injected as environment variables in all jobs contained on that block.
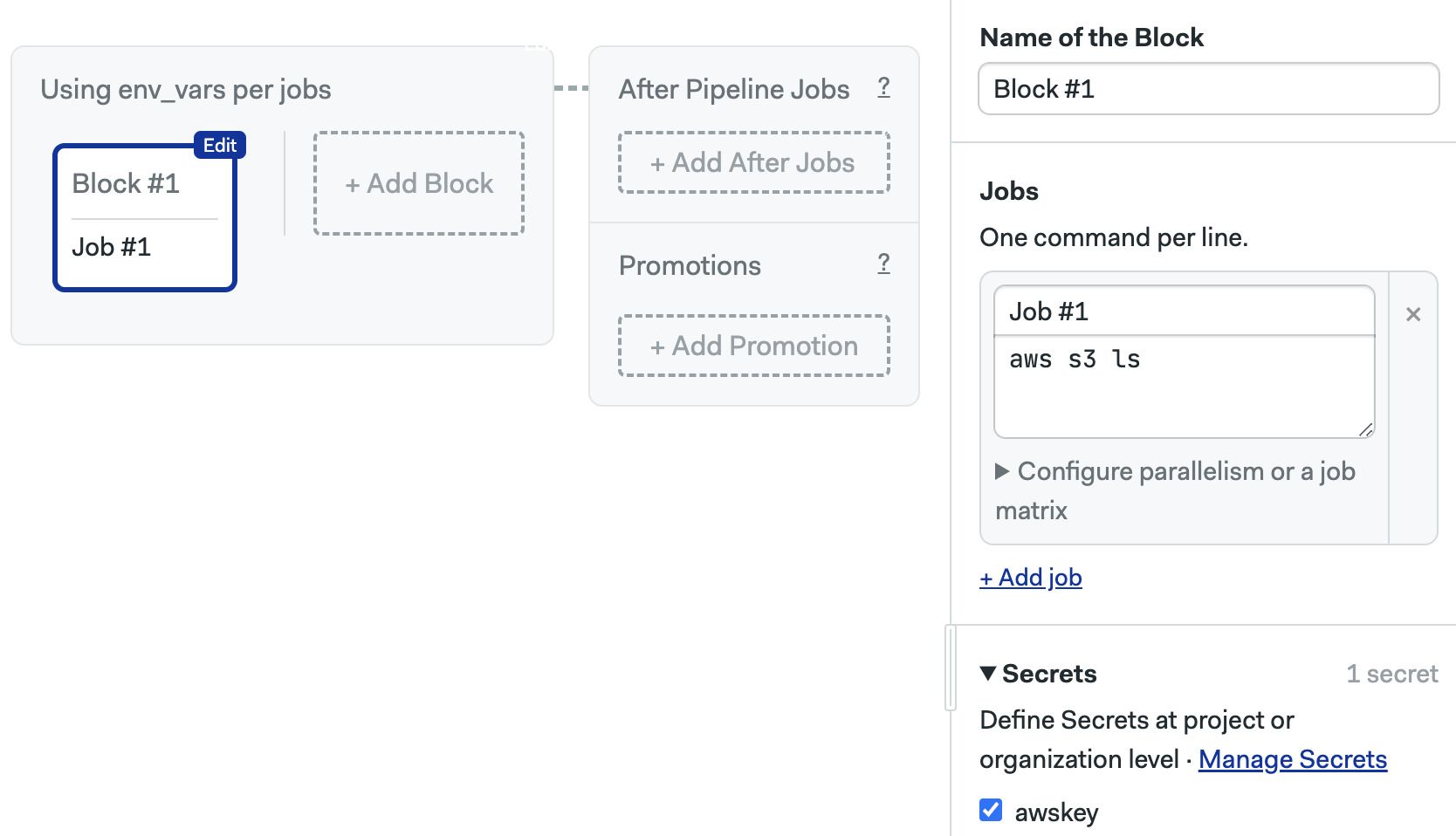
Complete example
The following comparison shows how to build and test a Ruby on Rails project on Jenkins and on Semaphore.
- Jenkins
- Semaphore
This pipeline runs all the tests in different sequential stages.
pipeline {
agent any
environment {
RAILS_ENV = 'test'
}
stages {
stage('Scan Ruby') {
agent { label 'ubuntu' }
steps {
// Checkout code
checkout scm
// Set up Ruby
sh '''
curl -sSL https://get.rvm.io | bash -s stable --ruby=$(cat .ruby-version)
source /usr/local/rvm/scripts/rvm
bundle install
'''
// Scan for common Rails security vulnerabilities
sh 'bin/brakeman --no-pager'
}
}
stage('Scan JS') {
agent { label 'ubuntu' }
steps {
// Checkout code
checkout scm
// Set up Ruby
sh '''
curl -sSL https://get.rvm.io | bash -s stable --ruby=$(cat .ruby-version)
source /usr/local/rvm/scripts/rvm
bundle install
'''
// Scan for security vulnerabilities in JavaScript dependencies
sh 'bin/importmap audit'
}
}
stage('Lint') {
agent { label 'ubuntu' }
steps {
// Checkout code
checkout scm
// Set up Ruby
sh '''
curl -sSL https://get.rvm.io | bash -s stable --ruby=$(cat .ruby-version)
source /usr/local/rvm/scripts/rvm
bundle install
'''
// Lint code for consistent style
sh 'bin/rubocop -f github'
}
}
stage('Test') {
agent { label 'ubuntu' }
steps {
// Install packages
sh 'sudo apt-get update && sudo apt-get install --no-install-recommends -y curl libjemalloc2 libvips sqlite3'
// Checkout code
checkout scm
// Set up Ruby
sh '''
curl -sSL https://get.rvm.io | bash -s stable --ruby=$(cat .ruby-version)
source /usr/local/rvm/scripts/rvm
bundle install
'''
// Run Rake tasks
sh '''
cp .sample.env .env
bundle exec rake db:setup
bundle exec rake
'''
// Run tests
sh 'bin/rails db:test:prepare test test:system'
}
}
}
post {
always {
// Clean up
deleteDir()
}
}
}
The following commands in a job run the same CI procedure. You can optimize for speed by splitting the tests into different jobs.
sudo apt-get update
sudo apt-get install --no-install-recommends -y curl libjemalloc2 libvips sqlite3
sem-version ruby 3.3.4
checkout
cache restore
bundle install --path vendor/bundle
cache store
cp .sample.env .env
bundle exec rake db:setup
bundle exec rake
bin/brakeman --no-pager
bin/importmap audit
bin/rubocop -f github
bin/rails db:test:prepare test test:system